2019/6/30 外国語教育メディア学会(LET)関⻄⽀部メソドロジー研究部会2019年度第1回研究会@福岡大学にて,上記のタイトルのワークショップを行いました。こちらは使用したスライドです。
AWSuM日本語版マニュアル
AWSuM User’s Manual [English]
AWSuM v1.10 released
I’m excited to announce the release of the updated version of AWSuM.
With this update, it is now possible to (1) search the left of the target words (1L to 3L). And if you use an asterisk in the search, (2) AWSuM shows you the words used in the place of the asterisk. You can also generate (3) concordance lines to examine how words are used in context. Isn’t it awesome or what?
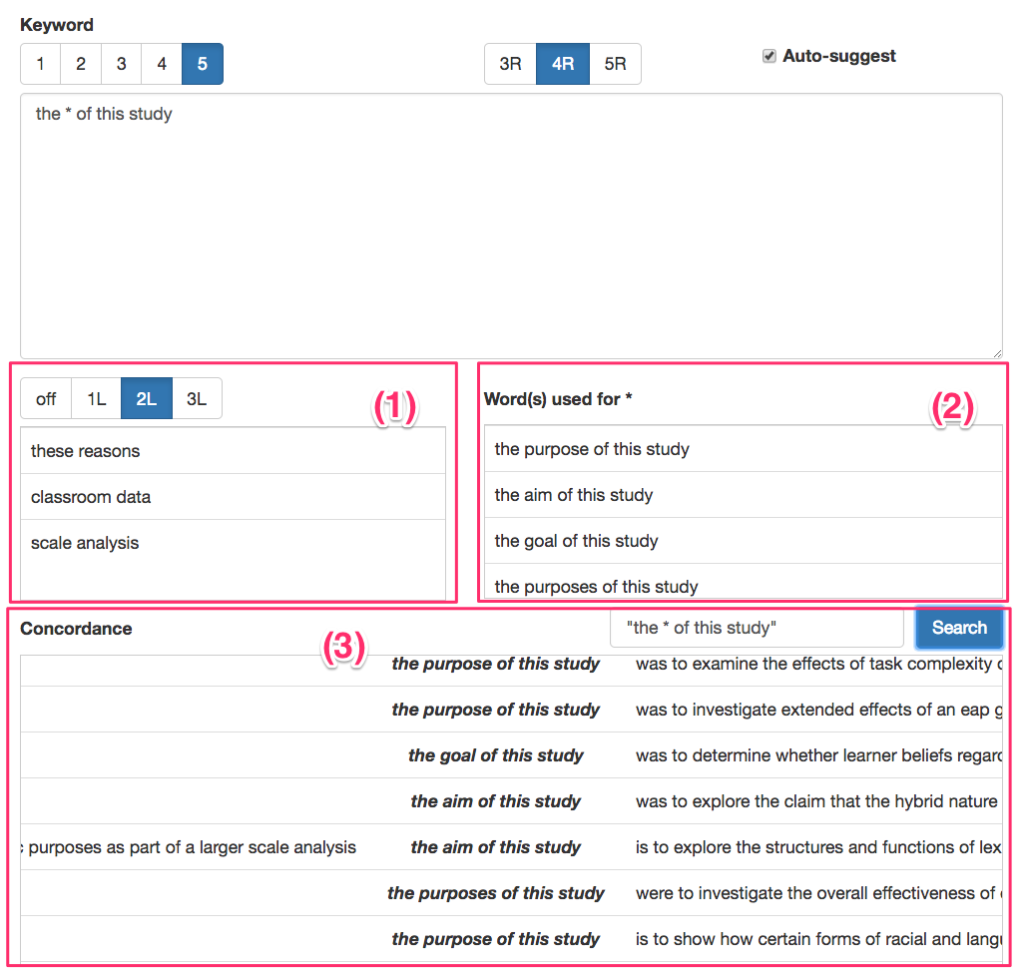
For those of you who don’t know what AWSuM is, here’s the introductory video.
The complete manual will be available in a few weeks.
「職業としての研究者」
長い引用ですが,村上春樹の『職業としての小説家』(2015) から。

pp. 26–27
「というわけで僕は,長い年月飽きもせずに(というか)小説を書き続けている作家たちに対して—つまり僕の同僚たちに対して,ということになりますが—一様に敬意を抱いています。当然のことながら,彼らの書く作品のひとつひとつについては個人的な好き嫌いはあります。でもそれはそれとして,二十年,三十年にもわたって職業的小説家として活躍し続け,あるいは生き延び,それぞれに一定数の読者を獲得している人たちには,小説家としての,何かしら優れた強い核(コア)のようなものが備わっているはずだと考えるからです。小説を書かずにはいられない内的なドライブ。長期間にわたる孤独な作業を支える強靭な忍耐力。それは小説家という職業人としての資質,資格,と言ってしまってもいいかもしれません。
小説をひとつ書くのはそれほどむずかしくない。優れた小説をひとつ書くのも,人によってはそれほどむずかしくない。簡単だとまでは言いませんが,できないことではありません。しかし小説をずっと書き続けるというのはずいぶんむずかしい。誰にでもできることではない。そうするには,さっきも申し上げましたように,特別な資格のようなものが必要になってくるからです。それはおそらく「才能」とはちょっと別のところにあるものでしょう。
じゃあ,その資格があるかどうか,それを見分けるにはどうすればいいか?答えはただひとつ,実際に水に放り込んでみて,浮かぶか沈むかで見定めるしかありません。乱暴な言い方ですが,まあ人生というのは本来そういう風にできているみたいです。それにだいたい小説なんか書かなくても(あるいはむしろ書かないでいる方が),人生は聡明に有効に生きられます。それでも書きたい,書かずにはいられない,という人が小説を書きます。そしてまた,小説を書き続けます。」
ちょっと違うところもあるけど,小説を「論文」,小説家を「研究者」に置き換えると,「職業としての研究者」(特に文系研究者)がやっていることに近くなる。
複数の Mac での Mendeley ライブラリと Dropbox(pdf)の同期
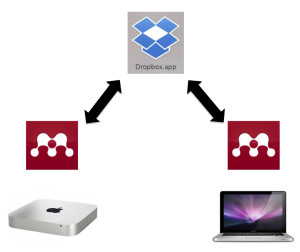
ずっとやりたかったこと
Mendeley を使い始めて6年ぐらいになりますが,ずっとやりたかったけどできなかった,Mac 1 <—> Dropbox(論文 pdf ファイル) <—> Mac 2, 3… という同期。
とにかく,どの Mac で開いても,同じ Mendeley ライブラリの情報(←これは当たり前にできる),そして Dropbox に保存している該当論文 pdf を開くことができるようにしたい(←これができなかった)。
英語でも日本語でも検索してみるとそういうニーズはあることがわかります。
「難しい設定は何もしなくても,Mendeley の File Organizer を同じDropboxのパスにして,設定も同じにしておけば勝手にできますよ」的な都市伝説もあったりするけど,なかなかそんな簡単にはいかないです。
本当に一番簡単な方法は,Mendeley の有料プラン web space を使うことです。毎月$4.99払えば5G まで,$9.99払えば10GB までは Web 版の Mendeley とすべての Mendeley Desktop で pdf の同期もできます(月$14.99だと無制限)。でも,私は Dropbox を有料プランにしているため,なんだかもったいない気がして,「どうにか Mendeley は無料のままでできないかな」と思いつつ,はや数年…
そして重たい腰をあげ試行錯誤の末,今日やっと同期できるようになったのでメモ。
基本的には,ここに書いてある方法で問題ありませんでした。
環境は,OS X El Capitan バージョン10.11.3,Mendeley Desktop バージョン1.16.1です。
#1 Dropbox の設定
Dropbox の中に,Mendeley というフォルダを作り,その中に db と pdf というフォルダを作ります。論文の pdf ファイルは pdf フォルダの中に入れておきます。
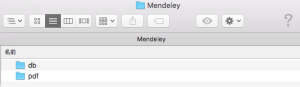
#2 すべての Mac の Mendeley Desktop の設定
どの Mac の Mendeley でも,Mendeley Desktop > Preferences > File Organizer で,以下のように Dropbox の Mendeley というフォルダの中に論文 pdf ファイルを入れるフォルダを作ります。
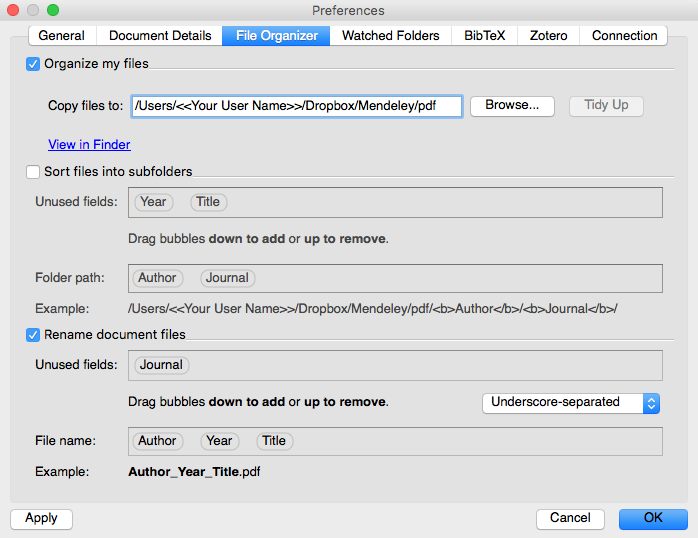
そして,どの Mac でも,/Users/<<Your User Name>>/Dropbox/Mendeley/pdf というパスになるように(<<Your User Name>>は自分のユーザー名が入る),”File Organizer” の設定をすべての Mac で同じにします。”Watched Folders” は(いらんことをするので特にうまく使えてない場合は)設定しないほうがよいと思います。
#3 母艦 Mac の設定
ターミナルを起動(アプリケーション > ユーティリティ > ターミナル.app)し,以下を1行ずつ入力(コピペで OK)。”Application\ Support” の \ はメタ文字のエスケープで,半角スペースを示します。
cd ~/Library/Application\ Support
cp -r Mendeley\ Desktop/ ~/Dropbox/Mendeley/db/
mv Mendeley\ Desktop/ _backup_Mendeley_Desktop/
ln -s ~/Dropbox/Mendeley/db/Mendeley\ Desktop .
[2016.12.23追記] この最後の行でシンボリックリンクを貼った後に,mkdirで空のフォルダを~/Dropbox/Mendeley/dbに置かないと,エラーになります。(初回の場合はそのフォルダがないため。)
それぞれの行でやっていることは以下です。
- Library の中の Application Support フォルダに移動。
- Library の中の Application Support フォルダにある,Mendeley Desktop の内容を,Dropbox の Mendeley フォルダの中に作成しておいた,db にコピー。
- backup_Mendeley_Desktop というフォルダを Library の Application Support の中に作り,Mendeley Desktop のバックアップファイルを作成(これで Mendeley Desktop はなくなる)。※ もし,Mendeley が開かなくなったりした場合は,Mendeley Desktop というフォルダを Library の中の Application Support に再度作成し,_backup_Mendeley_Desktop フォルダの中身をコピー(移動)すれば大丈夫。
- Library の Application Support の中に,Dropbox > Mendeley > db にある,Mendeley Desktop のエイリアス(alias)を作成する。
#4 その他の Mac の設定(2台以上でも可能)
ターミナルを起動(アプリケーション > ユーティリティ > ターミナル.app)し,以下を1行ずつ入力(コピペで OK)。
cd ~/Library/Application\ Support
mv Mendeley\ Desktop/ _backup_Mendeley_Desktop/
ln -s ~/Dropbox/Mendeley/db/Mendeley\ Desktop .
それぞれの行でやっていることは以下です。
- Library の中の Application Support フォルダに移動。
- backup_Mendeley_Desktop というフォルダを Library の Application Support の中に作り,Mendeley Desktop のバックアップファイルを作成(これで Mendeley Desktop はなくなる)。
- Library の Application Support の中に,Dropbox > Mendeley > db にある,Mendeley Desktop のエイリアス(alias)を作成する。
実は考え方はいたってシンプル
- 母艦 Mac の Mendeley Desktop の内容を,Dropbox の db フォルダに移す。
- 母艦 Mac のもともと Mendeley Desktop フォルダがあった場所には,Dropbox の db フォルダに移した Mendeley Desktop のエイリアスを置いておくことにより,母艦 Mac の Mendeley は常に Dropbox 内のデータベースを利用することになる。
- その他の Mac でも,Mendeley のデータベースは,常に Dropbox を参照する設定にすることによって,すべての Mac でデータベースの同期を可能にしている。
- 結局は,Dropbox にデータベースも pdf も両方置いている。
これによって,Mendeley > pdf フォルダに追加される論文ファイルは,必ずどの Mac でも見ることができるし,pdf に入れたハイライトや下線ももちろん共有されます。環境によって,pdf が添付されてたり,されていなかったりということがこれまでありましたが,これで,いちいちファイルを Dropbox の Mendeley フォルダで探す手間が省けるので,だいぶ快適になりました。
ただし,iOS では pdf は同期されないので,以下のように特定のフォルダを Mendeley のライブラリで作って,そのフォルダ内の pdf は同期するように設定するというような工夫が必要です。
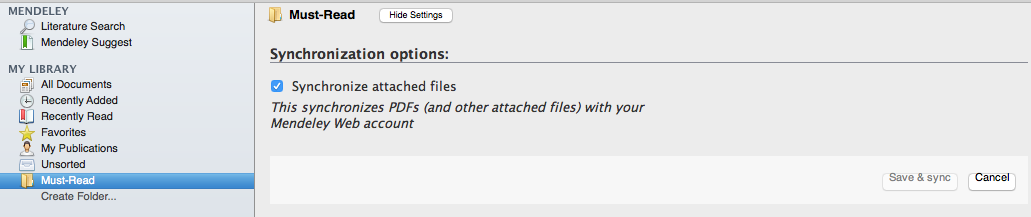
Mac 以外の場合
Windows でのやり方(はたぶんですが)はこちら。
Android で Mendeleyと連携したい というものもありました。
異なる PC での同期はだいぶやっかいそうですね。
とりあえず,Mac なら問題なくできます。
春ですので Mac を買いましょう。
AWSuM – Academic Word Suggestion Machine
英語論文執筆サポートツールを開発、公開しました。無料です。現在は応用言語学のみですが、他の分野も今後対応予定です。
We have developed a web-based writing support tool, which suggests most frequent 4-grams based on the sections and moves (rhetorical functions) of a research article. It is called AWSuM – Academic Word Suggestion Machine. At the moment, our database covers only the field of applied linguistics. But we will include other disciplinary fields in the future. Take a look at the introductory video. You will agree AWSuM is pretty awesome!
Useful resources (websites) for writing research papers in English
Here’s a list of websites I find useful in writing research papers in English.
Any feedback and suggestions are always welcome!
[Writing support tool]
WriteAway
As you type some words, WriteAway shows patterns (and examples) frequently used in written discourse.
[Word usage]
Lexipedia – Where words have meaning
Just The Word
[Dictionary/Thesaurus]
Memidex – free online dictionary and thesaurus
OneLook Dictionary Search
[Corpus]
Corpus of Research Articles
Springer Exemplar
StringNet Navigator 4.0
Sketch Engine: Open corpora
The Corpus of Contemporary American English (COCA)
BYU-BNC: British National Corpus
[Online proofreader]
Online Proofreader: Pre-Grade Your Essay | Paper Rater
Academic English Marking Mate
シンポジウム「コーパスを使った教育・研究 サポートツールの開発」
「コーパスを使った教育・研究 サポートツールの開発」(研究成果合同発表シンポジウム)を2016年2月22日(月)13:00-17:00に関西大学(岩崎記念館4F)で開催します。ご興味のある方はぜひお越しください。
http://mizumot.com/lablog/wp-content/uploads/2016/01/5535b6f8644e6c87a7242b1b6f514ab5.pdf
[R] ggplot2の覚書
langtest.jp の ANOVA で ggplot2 を使ったグラフを描けるようにしたときに,
いろいろと面倒だったので,覚書としていくつか参考になったサイトへのリンクを。
r / sciplot: overlapping whiskers in lineplot.CI
ggplot2についてちょっと勉強した(3) -themeを利用した外観の変更
ggplot2で全てのフォントを変えるオプション;めんどくさかった」
Cookbook for R | Legends (ggplot2)