PDF ThemeSort is a web‑based tool that uses Google’s Gemini API to analyze multiple PDF files with AI and automatically categorize them into common themes.
You can upload files via drag‑and‑drop and download them as a structured ZIP folder with a single click.
① How to Get Your Gemini API Key
This app uses Google’s Gemini API for AI‑powered content analysis.
💡 Note: Gemini API offers a free tier, but you may incur usage limits or fees depending on your usage.
② How to Use the App
1. Prepare Your PDF Files
Collect the PDFs you want to analyze (multiple files allowed)
Rename files with clear, descriptive names (e.g. Author - Year - Title.pdf)
Use the PDF Auto‑Renamer Tool, which extracts DOIs and fetches metadata (author, title, year) from Crossref to automatically rename academic PDFs.
By default, the app processes up to 5 pages or 2000 characters from each file
Mizumoto, A., Yasuda, S., & Tamura, Y. (2024). Identifying ChatGPT-generated texts in EFL students’ writing: Through comparative analysis of linguistic fingerprints. Applied Corpus Linguistics, 4, 100106. https://doi.org/10.1016/j.acorp.2024.100106
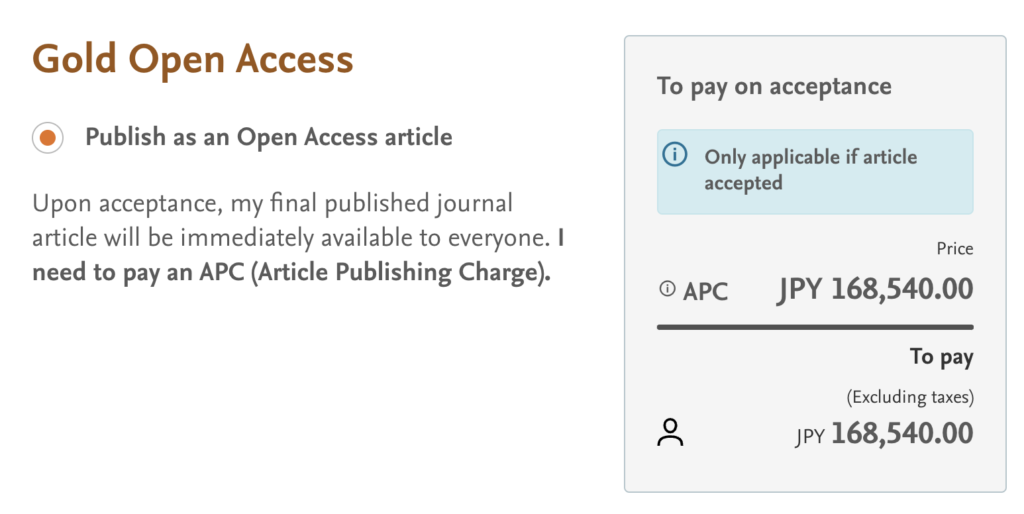
Open Access にするのに 18 万円かかりましたが、この程度であれば研究費で何とか賄うことができました。同じ Elsevier でも System はインパクト・ファクターが高いため、Open Access にする費用も 50 万円以上かかります。Open Science が重視される時代に、いつまで Article Processing Charge (APC) を支払い続けるのだろうと思いつつも、商業的な仕組みに依存せざるを得ない現状…
Applied Corpus Linguistics は相変わらず turnaround time(査読プロセス全体にかかる時間)が速く、2 か月で出版できました。
The emergence of Generative AI (GenAI), particularly ChatGPT, has introduced new challenges in teaching writing to English as a Foreign Language (EFL) learners. This study investigates the distinguishability of essays written by Japanese EFL learners compared to those generated by ChatGPT. By analyzing linguistic features, the research aims to determine whether AI-generated texts can be identified and how ChatGPT influences student writing.
Methodology
Participants: 140 first-year university students in Japan
Data Collection:
125 students wrote essays independently
13 students used ChatGPT for proofreading
2 students had ChatGPT write the entire essay
An additional 123 essays were generated by ChatGPT for comparison
Analysis: Natural Language Processing (NLP) techniques were used to extract linguistic features, and machine learning (random forest classification) was applied to differentiate human-written and AI-generated essays.
Clear distinctions between human-written and AI-generated essays
ChatGPT-generated essays exhibited higher lexical diversity, greater syntactic complexity, and more nominalization.
Human-written essays contained more modals, epistemic markers, and discourse markers.
ChatGPT-generated texts had significantly fewer grammatical errors and a higher word count.
NLP-based machine learning models can effectively identify ChatGPT-generated texts
The random forest classification model achieved 100% accuracy in distinguishing AI-generated essays (97.8% accuracy even when some linguistic features were excluded).
Characteristics of essays with partial ChatGPT use
Essays edited with ChatGPT retained human-like syntactic patterns but had significantly fewer errors.
Error-free writing was a key indicator of ChatGPT-assisted revisions.
Conclusions and Educational Implications
Need for clear guidelines on AI usage
Institutions should establish ethical policies for AI use and communicate them to students.
Integration of AI into writing education
AI can be beneficial for brainstorming and revision but should not replace the cognitive writing process.
Strategies should be implemented to ensure students use AI as a learning tool rather than a substitute for writing skills.
Reevaluation of writing assessment criteria
Educators should reconsider assessment methods to focus on students’ thought processes and engagement rather than just the final product.
This study highlights the impact of ChatGPT on EFL writing education, providing valuable insights into AI detection and responsible AI integration in academic settings.
以下に書いていない日本語の記事や in press のものを含むと2年間で30本以上になりました。Good job, 自分。2025年はもう少し健康になることを心がけます…
As I look back on 2024, it has been a year filled with daily busyness and challenges, yet one marked by significant academic accomplishments. Continuing from 2023, I successfully published a substantial number of papers, exceeding 30 over the past two years, including Japanese articles and those currently in press. Reflecting on these achievements, I want to take a moment to say, “Good job, me!”
This year has also been fulfilling in my role as a supervisor for both master’s and doctoral programs at the Graduate School of Foreign Language Education and Research at Kansai University. I have had the privilege of working with many dedicated students. My research has particularly focused on areas such as corpus linguistics and the application of generative AI in English education. To those interested in pursuing a master’s or doctoral degree, I encourage you to explore our programs. The graduate school offers fully remote courses, making it accessible to all (though the master’s program is limited to residents of Japan). https://www.kansai-u.ac.jp/fl/en/e-graduate/
Looking ahead to 2025, my goal is to prioritize my health. Amid the demands of research and writing, I plan to focus more on maintaining a balanced and healthier lifestyle. Here’s to another year of growth and success!
Mizumoto, A., Yasuda, S., &
Tamura, Y. (2024). Identifying ChatGPT-generated texts in EFL students’
writing: Through comparative analysis of linguistic fingerprints. Applied
Corpus Linguistics, 4, 100106. https://doi.org/10.1016/j.acorp.2024.100106
Mizumoto, A., Shintani, N.,
Sasaki, M., & Teng, M. F. (2024). Testing the viability of ChatGPT as a
companion in L2 writing accuracy assessment. Research Methods in Applied
Linguistics, 3(2), 100116. https://doi.org/10.1016/j.rmal.2024.100116
Allen, T. J., & Mizumoto,
A. (2024). ChatGPT over my friends: Japanese English-as-a-foreign-language
learners’ preferences for editing and proofreading strategies. RELC Journal.
https://doi.org/10.1177/00336882241262533
Yabukoshi, T., & Mizumoto,
A. (2024). Incorporating online writing resources into self‐regulated learning
strategy-based instruction: An intervention study. Journal of Computer
Assisted Learning, 40(6), 3486–3504. https://doi.org/10.1111/jcal.13081
Yabukoshi, T., & Mizumoto,
A. (2024). University EFL learners’ use of technology and their perceived
difficulties in academic writing. LET Kansai Chapter Collected Papers, 22,
117–129. https://doi.org/10.50924/letkansai.22.0_117
Huang, J., & Mizumoto, A.
(2024). Examining the relationship between the L2 motivational self system and
technology acceptance model post ChatGPT introduction and utilization. Computers
and Education: Artificial Intelligence, 100302. https://doi.org/10.1016/j.caeai.2024.100302
Huang, J., Mizumoto, A., &
Bailey, B. (2024). Examining the effects of the L2 learning experience on the
ideal L2 self and ought-to L2 self in a Japanese university context. International
Journal of Applied Linguistics. https://doi.org/10.1111/ijal.12659
Alamer, A., Teng, M. F., &
Mizumoto, A. (2024). Revisiting the construct validity of Self-Regulating
Capacity in Vocabulary Learning Scale: The confirmatory composite analysis
(CCA) approach. Applied Linguistics, amae023. https://doi.org/10.1093/applin/amae023
Teng, M. F., Mizumoto, A., & Takeuchi, O. (2024). Understanding
growth mindset, self-regulated vocabulary learning, and vocabulary knowledge. System,
122, 103255. https://doi.org/10.1016/j.system.2024.103255
Teng, M. F., & Mizumoto, A. (2024). Validation of metacognitive
knowledge in vocabulary learning and its predictive effects on incidental
vocabulary learning from reading. International Review of Applied
Linguistics in Language Teaching. https://doi.org/10.1515/iral-2023-0294
Teng, F., & Mizumoto, A. (2024). Developing and validating a
growth mindset scale in vocabulary learning. In A. Leis, Å. Haukås, N. Lou,
& S. Nakamura (Eds.), Mindsets in language education. Multilingual
Matters.
Mizumoto, A., & Eguchi, M. (2023). Exploring the potential of
using an AI language model for automated essay scoring. Research Methods in
Applied Linguistics, 2(2), 100050. https://doi.org/10.1016/j.rmal.2023.100050
Mizumoto, A. (2023). Data-driven learning meets generative AI:
Introducing the framework of metacognitive resource use. Applied Corpus
Linguistics, 3(3), 100074. https://doi.org/10.1016/j.acorp.2023.100074
Mizumoto, A. (2023). Calculating the relative importance of multiple
regression predictor variables using dominance analysis and random forests. Language
Learning, 73(1), 161–196. https://doi.org/10.1111/lang.12518
Hiratsuka, T., & Mizumoto, A. (2023). Exploratory-talk
instruction on EFL group discussion. Explorations in Teacher Development,
29(2), 13–20. https://td.jalt.org/index.php/volume-29/
Mizumoto, A., & Watari, Y. (2023). Identifying key grammatical
errors of Japanese English as a foreign language learners in a learner corpus:
Toward focused grammar instruction with data-driven learning. Asia Pacific
Journal of Corpus Research, 4(1), 25–42. https://doi.org/10.22925/apjcr.2023.4.1.25
Murata-Kobayashi, N., Suzuki, K., Morita, Y., Minobe, H., Mizumoto,
A., & Seto, S. (2023). Exploring the benefits of full-time hospital
facility dogs working with nurse handlers in a children’s hospital. PLOS ONE,
18(5), e0285768. https://doi.org/10.1371/journal.pone.0285768
Teng, M. F., & Mizumoto, A. (2023). The role of spoken
vocabulary knowledge in language minority students’ incidental vocabulary
learning from captioned television. Australian Review of Applied Linguistics,
46(2), 253–278. https://doi.org/10.1075/aral.22033.ten
Claudeに10分ぐらいでこさえてもらって爆誕w 95%なのか98%なのか語彙のカバー率が何%なら読解できているかを確認するのに使ってください。英文を貼り付けて、Load and Read Textをクリックし、知らない単語を読みながらクリックしたら何%なのか表示されます。https://t.co/r3jtCMfKKA
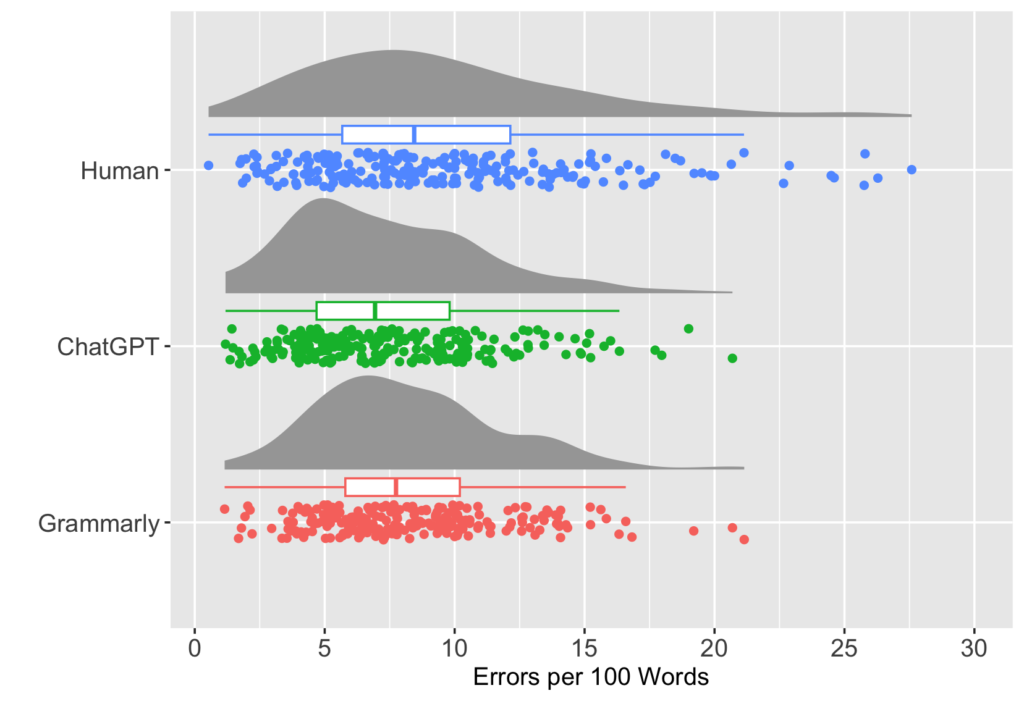
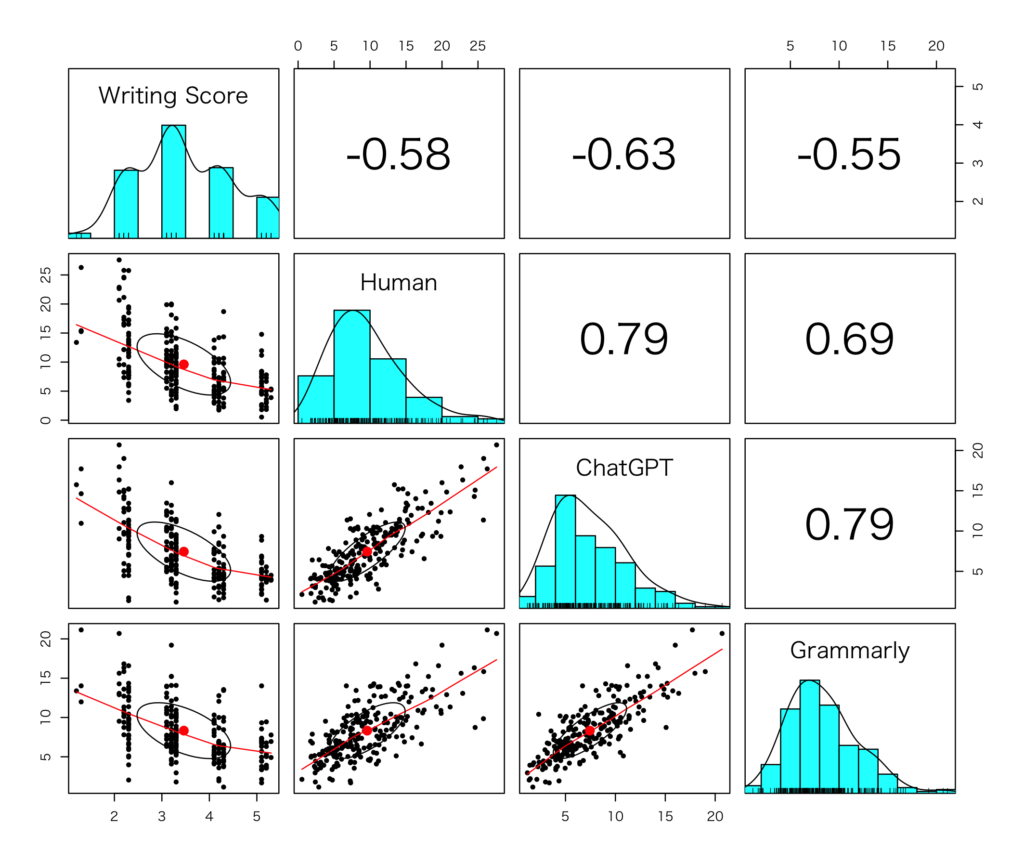
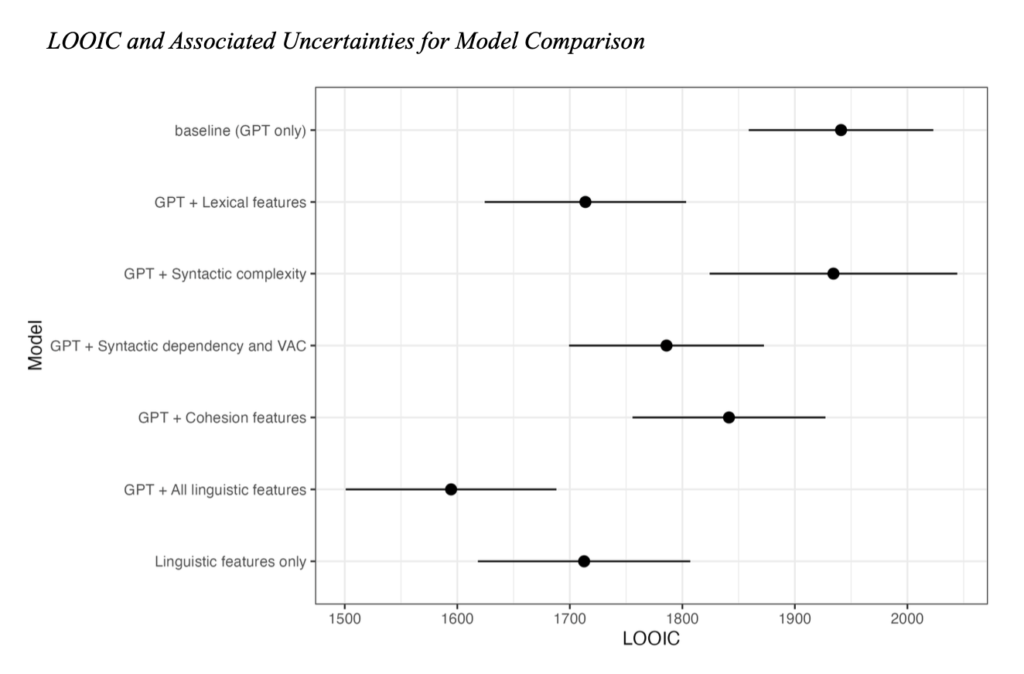
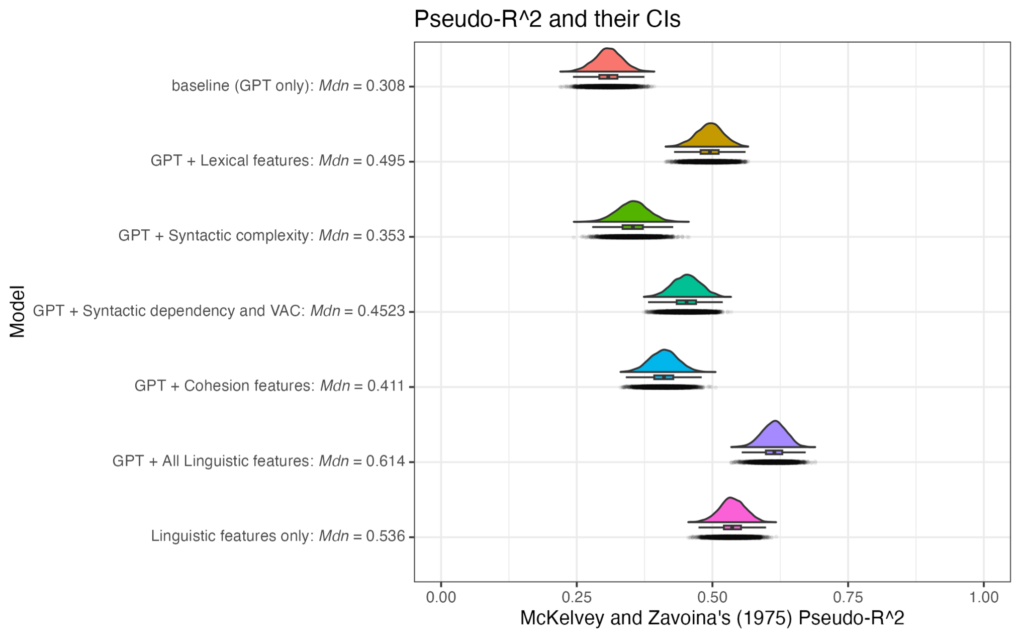
この論文は、昨年、Research Methods in Applied Linguistics で掲載された、ChatGPT を英語エッセイの自動評価に用いる可能性を検証した Mizumoto and Eguchi (2023) (詳しくはこちらを参照)の続編というような位置付けで、別のテーマ(ライティングにおける正確性)を取り上げているものです。同ジャーナルの Special Issue “Research Methods in L2 Writing” に掲載されます。
ChatGPT (GPT-4) による正確性測定は、Pfau et al. (2023) に倣い、1行1文に整形した元データに対して、OpenAI の API を使って分析を行いました。ブラウザ版のChatGPT (GPT-4) と同じ分析結果を得るため、パラメーターはデフォルトのまま以下のプロンプトを実行して分析し、errors per 100 words を算出しました。
Reply with a corrected version of the input sentence with all grammatical, spelling, and punctuation errors fixed. Be strict about the possible errors. If there are no errors, reply with a copy of the original sentence. Then, provide the number of errors.
Input sentence: {それぞれの文} Corrected sentence: Number of errors:
しかし、今回の共著者(新谷奈津子先生、佐々木みゆき先生、Mark Feng Teng 先生)は、L2ライティングの研究で世界的な先生方だったので、心強かったです。結局、最強チームのおかげですべてのコメントに対応できました。特に新谷先生には再投稿にあたり、全面的に書き直しをお手伝いいただきました。そのため、2回目の査読コメントはほとんどありませんでした。(さすが世界のシンタニ!)
Mizumoto, A., & Eguchi, M. (2023). Exploring the potential of using an AI language model for automated essay scoring. Research Methods in Applied Linguistics, 2(2), 100050. https://doi.org/10.1016/j.rmal.2023.100050
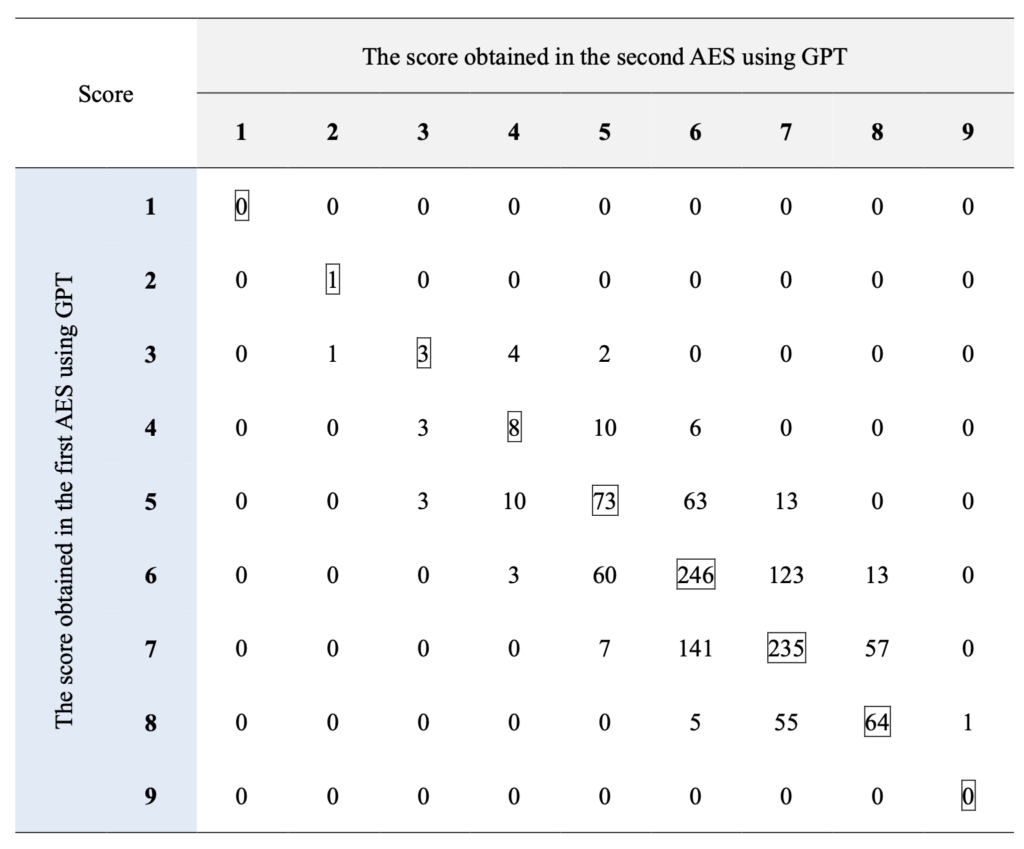
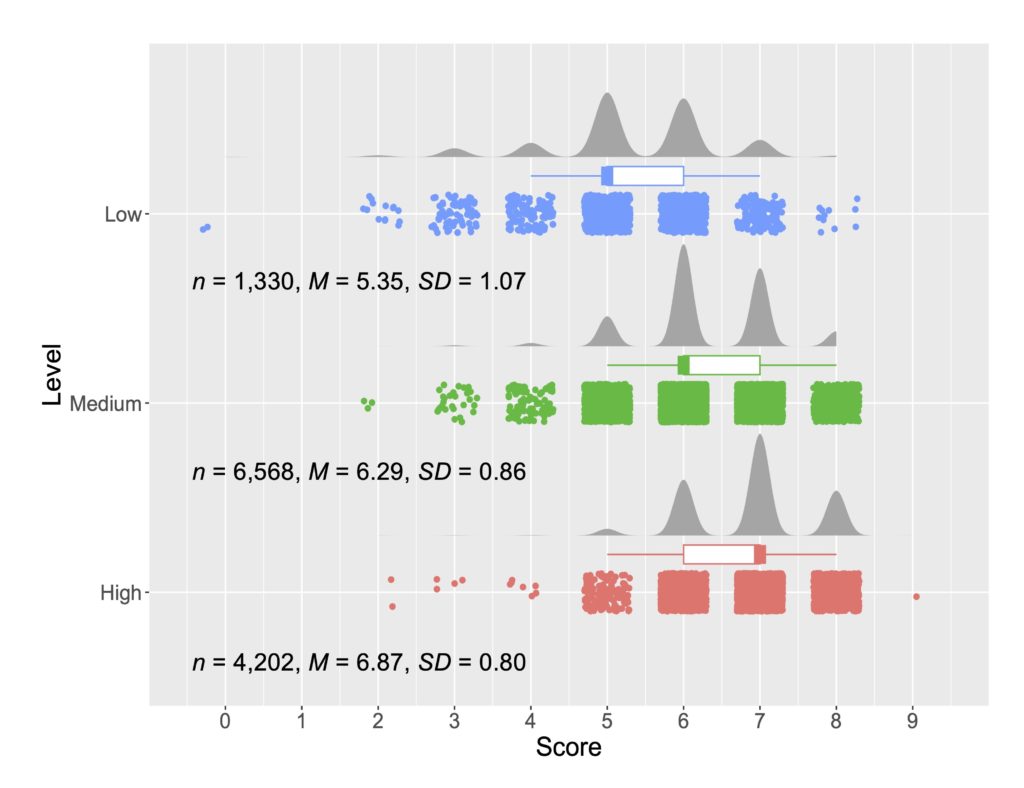
(Chat)GPTによる自動採点が、「本当の」スコア(やレベル)とどの程度一致するのかを調べる必要があったため、2006年と2007年にTOEFLを受験した12,100名のエッセイと、そのエッセイに対するレベル(low, medium, high)が付与されている学習者コーパスの ETS Corpus of Non-Native Written English (TOEFL11) を使用しました。
I would like you to mark an essay written by English as a foreign language (EFL) learners. Each essay is assigned a rating of 0 to 9, with 9 being the highest and 0 the lowest. You don’t have to give me the reason why you assign that specific score. Just report a score only. The essay is scored based on the following rubric.
応用言語学分野では、言語テスト系のジャーナルもたくさんあります。今回、テスティング関連のジャーナルに投稿せずに、なぜ Research Methods in Applied Linguistics (RMAL) に投稿したのかというと、査読結果が1ヶ月以内に返ってくるジャーナルだったからです。私もこのジャーナルの査読を何回かしたことがありますが、査読者も1ヶ月以内に結果を報告します。
In’nami, Y., Mizumoto, A., Plonsky, L., & Koizumi, R. (2022). Promoting computationally reproducible research in applied linguistics: Recommended practices and considerations. Research Methods in Applied Linguistics, 1(3), 100030. https://doi.org/10.1016/j.rmal.2022.100030
In the preparation of this manuscript, we employed ChatGPT (GPT-3.5 & 4) to enhance the clarity and coherence of the language, ensuring it adheres to the standards expected in scholarly journals. While ChatGPT played a role in refining the language, it did not contribute to the generation of any original ideas. The authors alone are responsible for any inaccuracies present in the manuscript. This research was supported by JSPS KAKENHI Grant No. 21H00553.
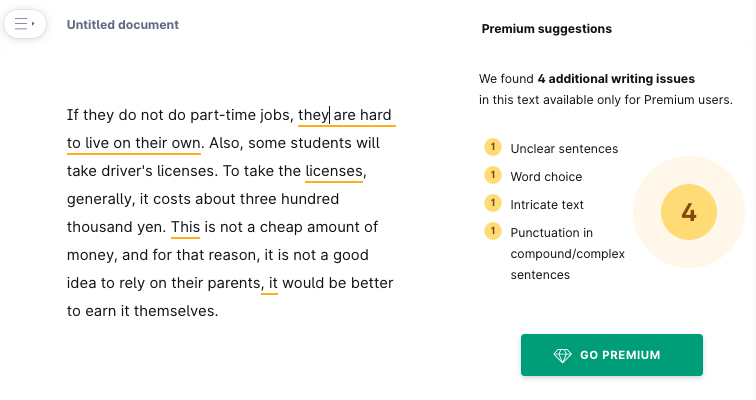
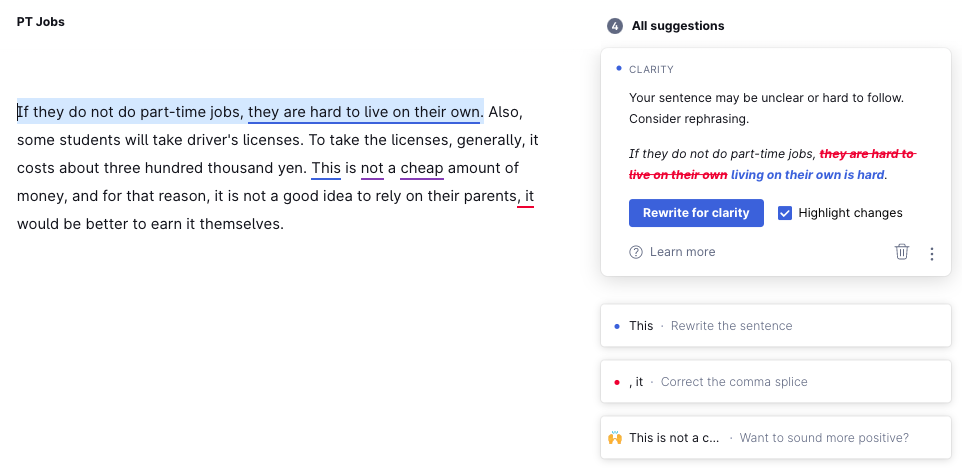
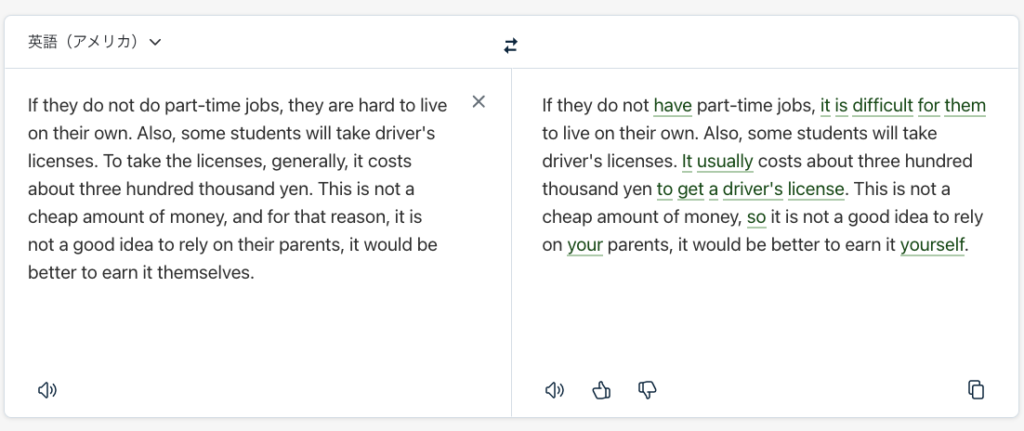
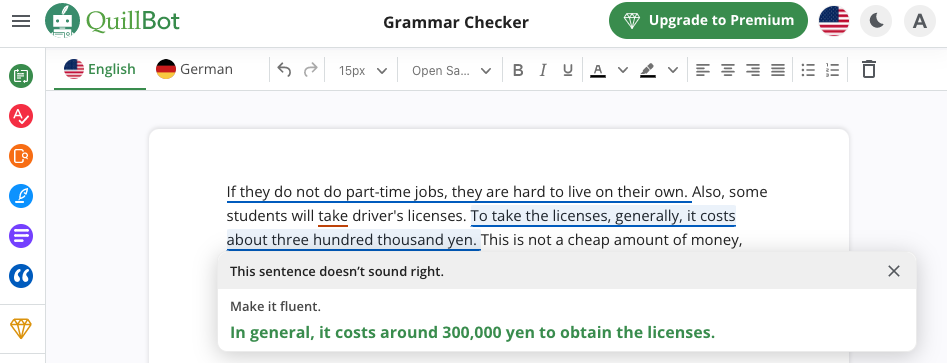
If they do not do part-time jobs, they are hard to live on their own. Also, some students will take driver’s licenses. To take the licenses, generally, it costs about three hundred thousand yen. This is not a cheap amount of money, and for that reason, it is not a good idea to rely on their parents, it would be better to earn it themselves.