「ChatGPTを使った英語エッセイの自動採点の精度はどの程度なのか?」ということを調査した論文が Research Methods in Applied Linguistics にアクセプトされました。応用言語学の研究分野で(Chat)GPTを使用している論文としては初になるのではないかと思います。

Mizumoto, A., & Eguchi, M. (2023). Exploring the potential of using an AI language model for automated essay scoring. Research Methods in Applied Linguistics, 2(2), 100050. https://doi.org/10.1016/j.rmal.2023.100050
*論文はジャーナルのウェブサイトでOpen Accessで公開されています。
今回は、論文の内容、および着想から出版までの記録などを書いておこうと思います。
着想
きっかけは、初詣の前に昼食を食べたレストランに入るまで、お客さんの長い列ができていたので、並びながらChatGPTでいろいろ遊んでたときのこと。「これってできるのかな?」と思いながらChatGPTにやらせてみた結果を見て驚いたのがこちらの呟き。
「ChatGPTでエッセイの採点ができるのなら、どの程度正確にできるのだろうか?」と思ったことが、今回の研究の始まりでした。
検証方法
使用したコーパス
(Chat)GPTによる自動採点が、「本当の」スコア(やレベル)とどの程度一致するのかを調べる必要があったため、2006年と2007年にTOEFLを受験した12,100名のエッセイと、そのエッセイに対するレベル(low, medium, high)が付与されている学習者コーパスの ETS Corpus of Non-Native Written English (TOEFL11) を使用しました。
TOEFL11は、その名前が示すとおり、11の異なる母語の英語学習者から無作為抽出されたエッセイデータが含まれいて、今回の研究の目的にはピッタリの学習者コーパスでした。
しかし、1月中旬に購入した時点で、TOEFL11は1,000ドル(135,591円)でした。私の2022年度の研究費が10万円しか残っておらず、35,591円は自分で支払うことになりました。(好きな研究とはいえジバーラはつらい。)
使用したGPTの種類
エッセイの自動採点には、GPT-3.5 シリーズとして2022年11月30日にChatGPTと同じタイミングでリリースされた OpenAI の text-davinci-003 モデルを使用しました。これは、text-davinci-003 がChatGPTと基礎となるモデルが同じであることから、ChatGPT(3.5)を使用した場合でも同様の結果が得られると考えたからです。
text-davinci-003 モデルは、PythonでOpenAIのAPIを使ってアクセスしました。これも、APIが10分の1の値段になる前だったので、1,000トークンで0.02ドルかかり、6つぐらいアカウントを作って数日かけて12,100ファイルを自動採点しました。結局これで10万円弱ジバーラという追加の罰ゲーム…(しかもGPT-4が2023年3月16日に発表されたため、2ヶ月前の話なのに「以前のモデルでの分析でありGPT-4を使ったほうが精度が高いだろう」という limitation を書かないといけないことに… 涙)
プロンプト
こちらのOSFに使用したPython、Rのコード、そしてその他のデータを公開していますが、プロンプトは以下のようなシンプルなものです。
I would like you to mark an essay written by English as a foreign language (EFL) learners. Each essay is assigned a rating of 0 to 9, with 9 being the highest and 0 the lowest. You don’t have to give me the reason why you assign that specific score. Just report a score only. The essay is scored based on the following rubric.
使用したルーブリックは IELTS TASK 2 Writing band descriptors (public version) でした。
「TOEFLのエッセイ採点なのにIELTSのルーブリック?」と思われた方は鋭いです。TOEFL iBT® Independent Writing Rubrics は5段階で、実際は0.5点の刻みが入りますが、ルーブリックほど細かい観点別になっておらず、ChatGPTで確認した限りエッセイの採点にあまり差が出ないことが多かったため、IELTSのルーブリックを使うことにしました。(ここは査読者完全スルー)
あと、ChatGPT で誰でも同じように自動採点ができるように、いくつかのサンプルエッセイやその採点をプロンプトに加えるということはせずに、Zero-shot のプロンプトを用いました。
自動採点のブレの確認
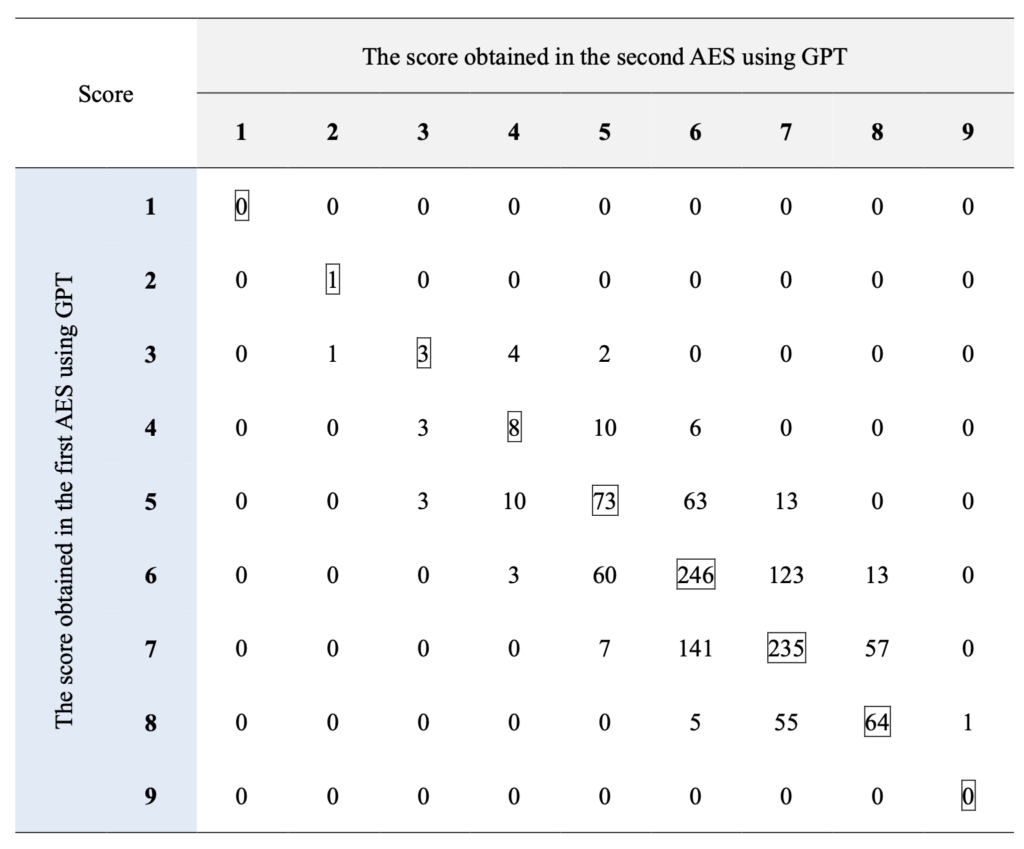
ChatGPTでも何度か同じエッセイを採点してみると、毎回、点数が同じというわけではなく、1~2点のブレがあるようだったので、どの程度同じ点数が一貫して得られるかということを確認するために、12,100本のエッセイのうち、全体のサンプルの構成(11の母語、エッセイのレベル)を反映した形で無作為抽出し、1,210本をもう一度自動採点しました。
なぜ12,100本すべてをもう一度自動採点しなかったかというと、これ以上ジバーラが増えると光熱費が高くなっている昨今、オール電化の水本家が冬を越して春が迎えられない可能性があったからです。その切実な状況とともに、TOEFL11がもともと無作為抽出のデータで構成されていたため、1,210本と言わずに100本だけでも全部のデータを使ったときと同じ結果が得られるということを何度か確認してわかっていたからです。無作為抽出は偉大。
2回採点した結果が以下のようなものでした。対角線上の四角で囲っている数値は1回目と2回目の採点が一致していたものです。だいたい、1~2点のブレに収まっており、2次の重み付きカッパ係数(Quadratic Weighted Kappa)を算出すると、0.682で「かなり一致している」(substantial agreement)という解釈になります。この結果から、GPTの自動採点はかなり安定しているため、分析に使用しても問題ないという判断をしました。
最強助っ人江口さん登場
ここまでの分析を自分でやってみて、先行研究では、結束性(cohesion)や統語的・語彙的複雑さ(syntactic/lexical complexity)のような言語的特徴量 (linguistic feature) を BERT のような transformer に追加することによって、自動採点の精度が高くなる、という報告を行っている研究がいくつかあったことを思い出しました。
「言語特徴も調べてみるか… 前もやったけど Python で自分でやるのは大変だな。誰か分析をお願いできないかな?」って思ったときに、すぐに思い浮かんだのが江口政貴さん(オレゴン大学博士後期課程)でした。江口さんといえば、Multi-Word Units Profiler を作ったり、国際トップジャーナルに論文をバンバン出している新進気鋭の研究者で、昨年夏に日本に帰国された際にもジバーラで東京まで会いに行って話をさせていただいた、私が尊敬する若手研究者なのです。
「いつか一緒に研究しましょう」って以前から言っていたので、お声掛けしたところ即ご快諾いただきました。ただし、博士論文執筆の大事な局面でのタイミングだったので結構ご負担になってしまったことを反省しています。
私からしたら、現役バリバリのメジャーリーガーが WBC で日本チームに合流したような感じだったので結構心強かったです。(ヌートバーか大谷翔平かどちらだろう江口さん?ダルビッシュではないな…)実際、査読者やエディターのコメントからも、江口さんに共著者で入ってもらったことはプラスに働いたことがわかりました。
結果
TOEFL11 の Low, Medium, High という3つのグループでGPTによる自動採点の点数の分布がどのようになっていたかを示しているのが以下の図です。
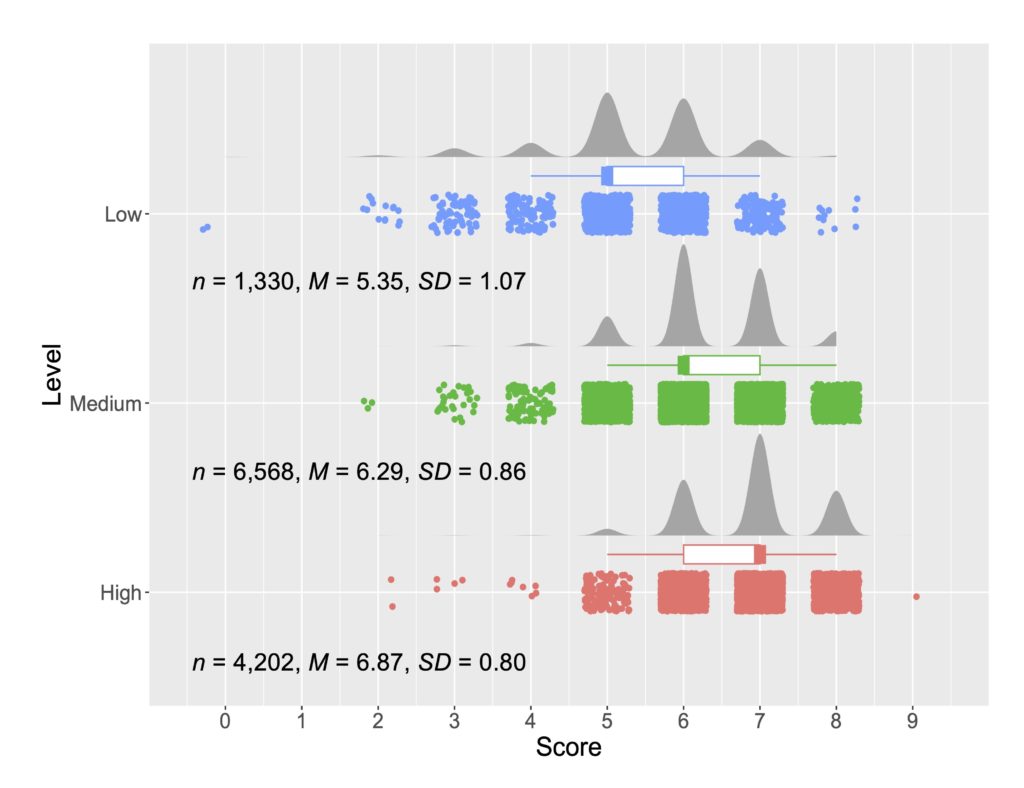
レベル間で点数の重複が多いですが、ある程度、違いがあるということが確認できます。つまり、GPTによる自動採点でTOEFL11のレベル分けが(完璧ではありませんが)再現できるということが言えそうです。統計的検定の結果や効果量などの詳細は論文をご確認ください。
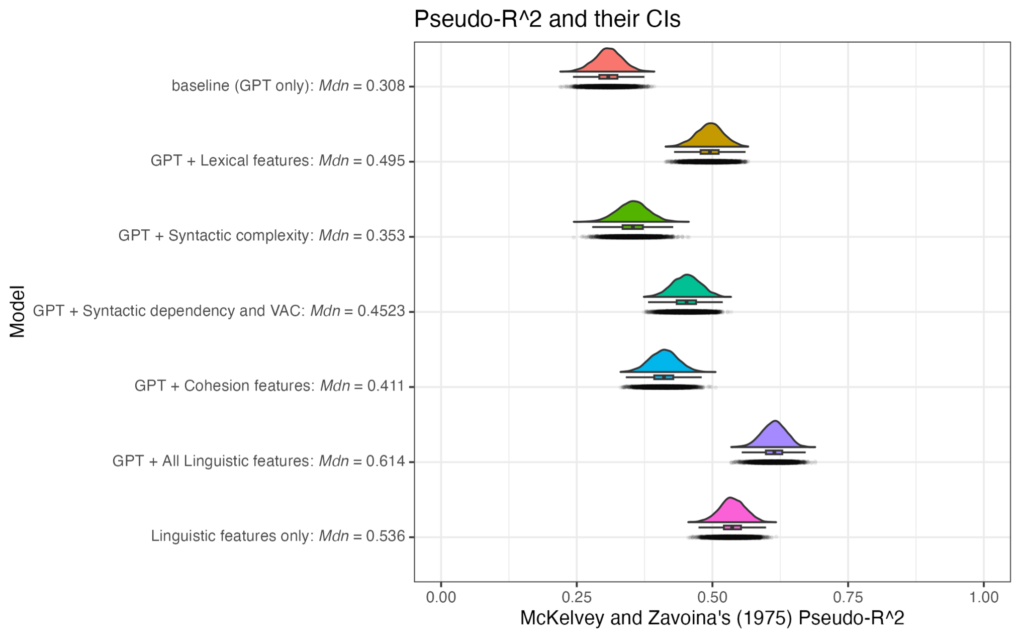
次に、言語的特徴量を入れることによって、予測の精度がどの程度変わるかを示したのが以下の図です。数値が低い方がモデルとして優れていると判断します。GPTだけよりも言語的特徴量を入れるほうが良いという結果になりました。
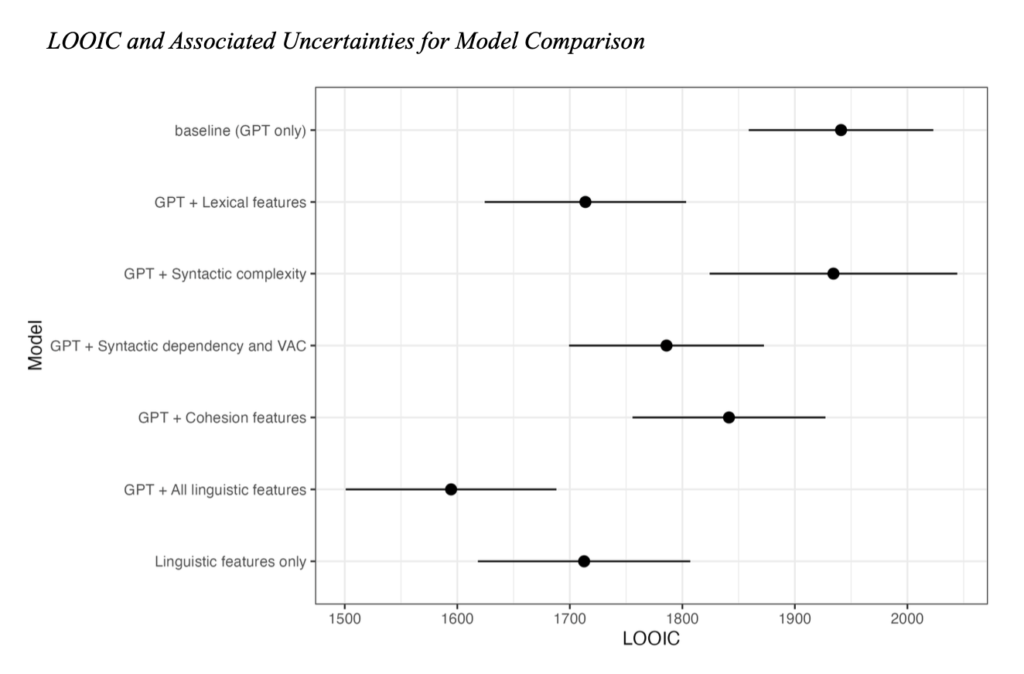
分散説明率(モデルでどの程度予測が正確にできるか)を見てみると、GPTだけよりも言語的特徴量を入れるほうが明らかに説明率が高くなっています。
結果のまとめ
- GPTだけで自動採点するとまあまあの精度。
- ハイステークスなテストに使えるレベルではない。
- 言語的特徴量を入れると精度が大幅に上がる
- 学習や指導、評価のサポート・ツールとしては使えるだろうというレベル。
- (これまでの自動採点で言われていることと同じで)GPTだけでは精度が高くないので、人間の採点も組み合わせたほうがよい。
なぜRMALに投稿したのか?
本題からは逸れますが、大事なことなので書いておきたいと思います。
応用言語学分野では、言語テスト系のジャーナルもたくさんあります。今回、テスティング関連のジャーナルに投稿せずに、なぜ Research Methods in Applied Linguistics (RMAL) に投稿したのかというと、査読結果が1ヶ月以内に返ってくるジャーナルだったからです。私もこのジャーナルの査読を何回かしたことがありますが、査読者も1ヶ月以内に結果を報告します。
2022年に第2著者として出版したこちらの論文でも、審査のスピードが異様なまでに早かったことを覚えています。
In’nami, Y., Mizumoto, A., Plonsky, L., & Koizumi, R. (2022). Promoting computationally reproducible research in applied linguistics: Recommended practices and considerations. Research Methods in Applied Linguistics, 1(3), 100030. https://doi.org/10.1016/j.rmal.2022.100030
今回のトピックであるGPTは上述のように、数ヶ月前のモデルでも刷新されて、すぐに古くなってしまいますので、新鮮さが命です。そのため、テスティング関連のジャーナルではなく、RMALに投稿しました。そして、今回はその作戦が成功しました。
RMALは2022年に始まったジャーナルなので、査読のバックログもないことが審査が早い要因かもしれませんが、それよりも、エディターの Dr. Shaofeng Li の以下のツイートからもわかるように、意識的にそうしているようです。
実際、3/28に2人目の査読者が結果を返してきた、その数時間後に Li 先生からアクセプトの連絡が届きました。ほぼ as is は初めての経験。
<記録>
2023年1月24日 論文執筆開始
2023年2月23日 投稿
2023年3月28日 アクセプト
日本の学会誌もこれぐらいのスピード感だったら魅力が増すのに、と思いつつ、自分が編集委員や査読者だったらツライのであまり大きな声では言えない…😂
このように、RMALはとても良いジャーナルですので、みなさんもなにかメソッド関連の論文があったら、投稿させると良いと思います。もし、リジェクトされたような場合は、LET関西支部メソドロジー研究部会の研究論集も、ぜひ投稿先としてご検討ください。
役に立ったツール
ChatGPT もそうですが、ここ数ヶ月で先行研究を探したり、読んだり、まとめたりというツールに AI 的なものが組み込まれてきていて、今回の論文執筆でも大活躍しました。
こちらは、そのような論文執筆サポートツールをまとめたものです。
「英語論文執筆プロセスで活用できるサポートツール」
こういうツールの使い方を知ることも、これからの研究者にとっては非常に重要ですので、3/9に以下の学内限定セミナーを行いました。以下の画像をクリックすると使用したスライドをご確認いただけます。

ChatGPTを中心に、このようなツールを活用したため、今回の論文では英文校正会社のチェックを受けずに、論文を出版することができました。
今回は、Elsevier のジャーナルだったので、The Use of AI and AI-assisted Technologies in Scientific Writing に明記されているように、論文の Acknowledgementには、ChatGPTをどのように使用したかを明記しています。
In the preparation of this manuscript, we employed ChatGPT (GPT-3.5 & 4) to enhance the clarity and coherence of the language, ensuring it adheres to the standards expected in scholarly journals. While ChatGPT played a role in refining the language, it did not contribute to the generation of any original ideas. The authors alone are responsible for any inaccuracies present in the manuscript. This research was supported by JSPS KAKENHI Grant No. 21H00553.
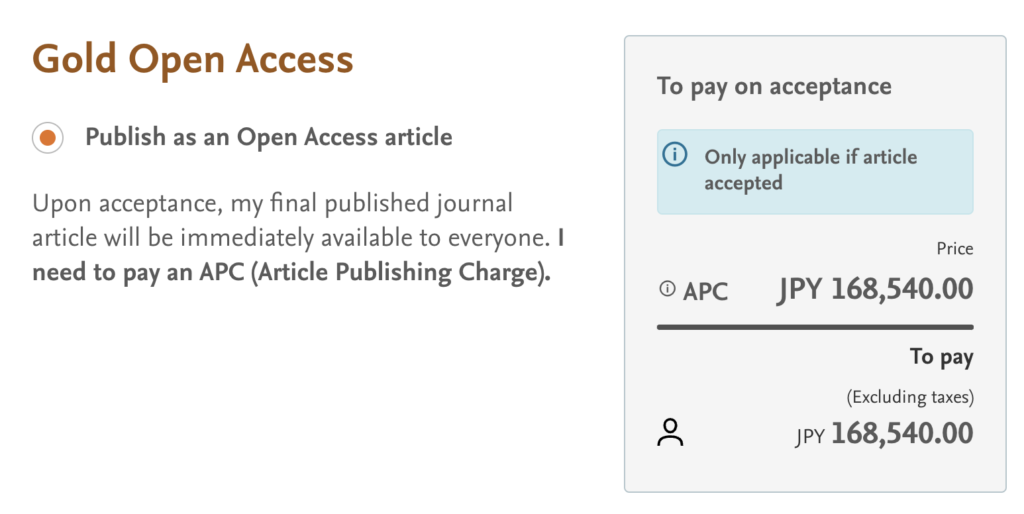
さいごに
今日から4月(新年度)になりましたので、この論文をオープン・アクセスにするための以下の費用がジバーラになることはなさそうです。なんという幸せなことなのでしょう。2023年度も関係者のみなさま、どうぞよろしくお願いいたします。